
소프트웨어가 하드웨어를 재정의하는 시대
인공지능 산업은 구글(Alphabet), 오픈AI(OpenAI), 앤트로픽(Anthropic)의 '빅 3' 구도로 빠르게 재편되고 있습니다. 이들은 각기 다른 전략과 기술로 AI의 미래를 정의하며 치열한 경쟁을 펼치고 있습니다. 특히 구글 딥마인드 CEO 데미스 하사비스가 향후 1년을 AI가 '실험실의 과학'에서 '일상의 제품'으로 전환되는 '통합의 해'로 선언하면서, 산업 전체가 새로운 변곡점을 맞이하고 있습니다.
더 이상 경쟁의 본질은 챗봇 성능을 넘어, AI를 구동하는 근본적인 아키텍처, 인프라, 그리고 지속 가능한 비즈니스 모델의 완결성으로 이동했습니다. 특히 구글이 제시한 혁신적인 AI 아키텍처는 단순한 소프트웨어 개선을 넘어, 반도체 산업의 물리적 구조까지 재편하는 거대한 파급효과를 만들어내고 있습니다. 소프트웨어의 청사진이 하드웨어의 미래를 그리는 새로운 시대가 개막한 것입니다.
본 글은 AI 빅 3의 경쟁 전략을 비교 분석하고, 구글의 기술적 혁신이 어떻게 메모리 반도체 산업의 질적 슈퍼사이클을 촉발하고 있는지 심층적으로 조명합니다.
AI Big 3의 전략적 차이: 세 가지 경쟁 모델
구글: 수직 계열화를 통한 엔드투엔드 생태계
구글의 핵심 전략은 '수직 계열화(Vertical Integration)'로 요약됩니다. 자체 설계한 AI 반도체 TPU부터 구글 클라우드 인프라, 프론티어 모델 Gemini, 그리고 검색·워크스페이스·안드로이드 등 수십억 명이 사용하는 서비스까지 '엔드투엔드 풀스택 구조'를 완성했습니다.
이 통합 구조는 구글에게 막대한 비용 우위를 제공합니다. 외부에서 고가의 GPU를 구매하고 클라우드를 임대해야 하는 경쟁사와 달리, 자체 인프라로 학습 및 추론 비용을 획기적으로 절감할 수 있습니다. 또한 전 세계 39억 대의 안드로이드 기기를 비롯한 방대한 플랫폼에 AI를 깊숙이 통합하여 자연스러운 생태계 확장과 막대한 데이터 확보가 가능합니다.
오픈AI: 퍼스트 무버의 시장 선점 전략
오픈AI는 ChatGPT를 통해 '퍼스트 무버(First Mover)'로서 막대한 사용자 기반과 브랜드 인지도를 확보했습니다. 이는 기술 표준을 선도하고 방대한 API 생태계를 구축하는 핵심 자산입니다.
그러나 엔비디아 GPU를 구매하고 마이크로소프트 애저 클라우드를 임대하는 '파트너 의존 모델'은 각 파트너에게 마진을 지불해야 하는 '마진 스태킹(Margin Stacking)' 구조로, 장기적인 비용 압박 요인이 될 수 있습니다. 핵심 인프라를 외부에 의존함에 따른 공급망 리스크와 기술 종속성도 잠재적 우려사항입니다.
앤트로픽: B2B 특화와 멀티 클라우드 전략
앤트로픽은 모델의 신뢰성과 안전성을 최우선으로 내세우며 기업 시장(B2B)을 집중 공략합니다. 규제가 엄격하고 데이터 보안이 중요한 금융, 법률, 헬스케어 등에서 강점을 발휘합니다.
인프라 측면에서는 AWS Trainium과 구글 클라우드 TPU를 모두 활용하는 '유연한 멀티 클라우드' 전략을 채택했습니다. 특정 플랫폼에 종속되지 않고 각 워크로드에 최적화된 인프라를 선택함으로써 비용 효율성을 높이고 공급망 리스크를 분산시킵니다.
전략 비교 요약
핵심 전략
- 구글: 칩-클라우드-모델-서비스의 완전한 수직 계열화
- 오픈AI: 선도적 모델과 대규모 사용자 기반 활용
- 앤트로픽: B2B 특화 및 신뢰성 강조
인프라 구조
- 구글: 자체 TPU 및 구글 클라우드
- 오픈AI: 엔비디아 GPU + 마이크로소프트 애저
- 앤트로픽: AWS + 구글 클라우드 멀티 클라우드
비용 구조
- 구글: 통합에 따른 비용 우위와 높은 마진
- 오픈AI: 외부 의존으로 인한 마진 스태킹
- 앤트로픽: 오픈AI 대비 높은 비용 효율성

구글의 기술적 돌파: Gemini 3.0과 근본적 아키텍처 혁신
프론티어 모델 성능의 선두주자
최신 프론티어 모델 경쟁에서 구글의 Gemini 3.0 Pro는 Artificial Analysis 및 LMArena 리더보드에서 Claude 4.5, GPT-5.1 등을 제치고 종합 1위를 기록했습니다. 특히 'Deep Think' 모드는 복잡한 수학, 과학 문제 해결에서 높은 추론 능력을 보이며, AI가 단순 정보 검색을 넘어 심층적 분석 파트너로 진화하고 있음을 입증했습니다.
하사비스가 제시한 향후 1년간의 핵심 기술 트렌드는 AI의 미래 방향을 명확히 보여줍니다.
- 완전한 멀티모달 통합: 텍스트, 이미지, 오디오, 비디오를 하나의 신경망에서 자유롭게 변환
- 시각 지능의 비약: 이미지의 의미론적 구조 파악과 정확한 인포그래픽 시각화
- 언어와 영상의 융합: 비디오의 내러티브, 감정, 문화적 맥락까지 이해
- 월드 모델의 대중화: 현실 세계의 물리 법칙과 공간 구조를 시뮬레이션
- 에이전트의 신뢰성 확보: 복잡한 다단계 작업을 자율적으로 완수
이러한 고도화된 기능들은 기존 컴퓨팅 아키텍처에 막대한 부담을 가하며, 소프트웨어와 하드웨어가 유기적으로 결합된 완전히 새로운 패러다임을 요구합니다.
AI의 근본적 진화: 기억상실증을 극복하는 Nested Learning
현재 거대언어모델(LLM)은 치명적인 약점을 안고 있습니다. 훈련이 끝나는 순간 지적 성장이 멈추는 '선행성 기억상실증'과 새로운 정보를 배우면 기존 지식을 잊어버리는 '파국적 망각(Catastrophic Forgetting)' 현상입니다. 세상은 매초 변화하는데 AI는 과거 데이터에 박제되어 있다면, 이 간극은 실시간 상호작용이 필요한 자율 에이전트와 월드 모델의 상용화를 가로막는 거대한 장벽이 됩니다.
구글은 이 근본적 문제를 해결하기 위해 'Nested Learning(중첩 학습)' 패러다임을 제시하고, 이를 구현한 'HOPE' 모델을 공개했습니다. 이 아키텍처는 추론(Inference)과 학습(Training)의 경계를 허물어, 추론하는 매 순간이 곧 학습이 되는 동적 유기체로 AI를 진화시킵니다.
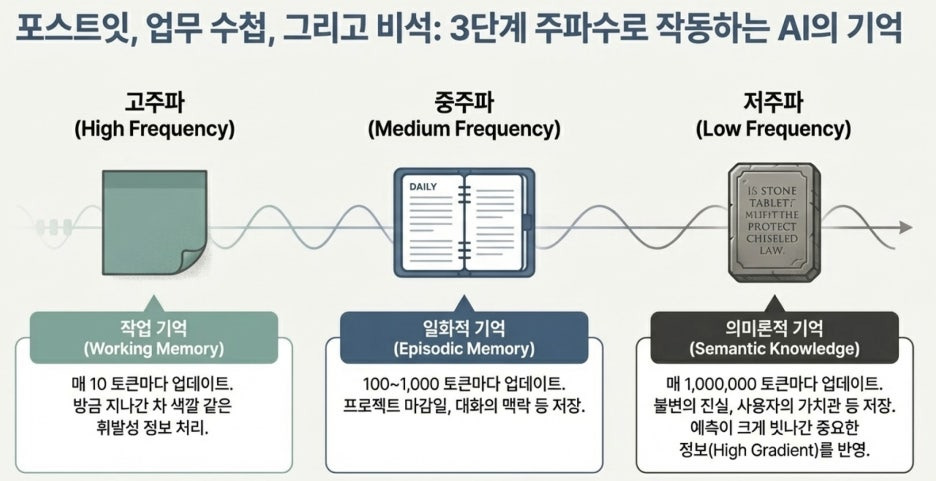
인간 뇌를 모방한 다층적 메모리 시스템
HOPE 모델의 핵심은 인간의 뇌가 단기 기억을 장기 기억으로 점진적으로 공고화하는 과정을 모방한 '연속체 기억 시스템(CMS)'입니다. 정보를 중요도와 시간 척도에 따라 각기 다른 주파수로 처리합니다.
작업 기억 (Working Memory)
- 인간의 예시: 포스트잇에 기록하듯, 방금 본 차의 색깔 같은 휘발성 정보
- AI 구현: 고주파 모듈 - 매 토큰 단위로 신경망을 업데이트하며 즉각적 정보 처리
일화적 기억 (Episodic Memory)
- 인간의 예시: 업무 수첩에 기록하는 대화 맥락이나 프로젝트 마감일
- AI 구현: 중주파 모듈 - 수백~수천 토큰 단위로 업데이트하며 대화 맥락 보관
의미론적 기억 (Semantic Knowledge)
- 인간의 예시: 비석에 새기듯 불변의 지식이나 핵심 가치관
- AI 구현: 저주파 모듈 - 수백만 토큰 단위로 매우 드물게 업데이트하며 세상의 법칙 저장
이 설계의 핵심은 신호 간섭의 제어입니다. 새로운 정보의 쓰나미(고주파 신호)가 몰려와도 물리적으로 격리된 고주파 모듈에서만 처리되고 소멸되어, 기존 지식이 저장된 저주파 모듈을 훼손하지 않습니다. AI가 무엇을 배울지 결정하는 핵심 동력은 '놀라움(Surprise)', 즉 '예측 오차에 의한 기울기의 크기(Gradient Norm)'입니다. 예측하지 못한 정보를 중요한 신호로 간주해 선택적으로 학습하고, 뻔한 정보는 노이즈로 무시하여 스스로 학습 과정을 조율합니다.
RAG를 넘어서는 진정한 지식의 내면화
Nested Learning의 가장 큰 전략적 함의는 외부 데이터베이스를 검색해 정보를 가져오는 RAG(검색 증강 생성) 방식의 한계를 넘어선다는 점입니다. RAG가 시험 중 참고서를 보는 '검색(Retrieval)'이라면, Nested Learning은 지식을 모델 내부에 실시간으로 내재화하는 '모수적 메모리(Parametric Memory)', 즉 진정한 '회상(Recall)'으로의 패러다임 전환입니다. 이는 인간처럼 단기 기억을 장기 기억으로 전환하며 경험을 통해 지속적으로 배우고 성장하는 '지속적 학습(Continual Learning)'을 구현합니다.
AI 검색의 패러다임 전환: 경제성 확보
구글은 이 혁신 기술을 자사의 핵심 서비스인 '검색'에 적용하며 패러다임을 주도합니다. 차세대 AI 검색은 사용자의 단일 질문을 여러 하위 질문으로 자동 확장하여 심층 리서치를 수행하는 '쿼리 팬 아웃(Query Fan-out)' 기술을 사용합니다. 이는 풍부한 답변을 제공하지만 일반 검색 대비 10~30배의 막대한 연산 비용을 발생시킵니다.
구글은 'MuVERA'라는 고효율 검색 알고리즘으로 이 문제를 해결했습니다. 3단계 필터링 구조로 연관성 낮은 데이터를 미리 걸러내고 핵심 정보만 정밀 대조하여, 불필요한 연산을 90% 이상 제거하면서도 검색 정확도는 오히려 향상시킵니다. 이는 고도화된 AI 검색의 경제성을 확보하고 대중화를 가능하게 하는 핵심 솔루션입니다.

소프트웨어가 하드웨어를 재편하다: 계층형 메모리 혁명
구글 AI 모델에서 정의된 추상적인 '학습 주파수' 개념은 이제 반도체 산업의 구체적인 부품 명세서로 번역되고 있습니다. 알고리즘이 데이터의 중요도와 업데이트 속도를 결정하면, 하드웨어가 그에 맞춰 가장 효율적인 위치에 데이터를 저장하고 처리해야 하는 새로운 시대가 개막했습니다. 소프트웨어가 HBM, CXL, SSD의 사양을 직접 지시하는 것입니다.
소프트웨어 주파수와 하드웨어 계층의 매핑
Nested Learning의 다중 주파수 모듈은 하드웨어 계층 구조에 직접 매핑됩니다.
HBM (Hot Tier) ← 고주파 모듈
- 역할: 초단기 작업 기억 처리
- 요구사항: 매 토큰마다 발생하는 가중치 수정을 위한 초고대역폭, 저지연 쓰기/읽기
- 연산 집약적 트래픽으로 기존 대비 메모리 트래픽 2배 이상 폭증
CXL DRAM (Warm Tier) ← 중주파 모듈
- 역할: 에피소드/맥락 기억 관리
- 요구사항: 알고리즘 예측에 따라 필요한 데이터를 HBM으로 미리 전송하는 스마트 파이프라인
- 지능형 데이터 프리페칭으로 지연 시간 은닉
NAND eSSD (Cold Tier) ← 저주파 모듈
- 역할: 장기 지식 저장소
- 요구사항: 페타바이트급 데이터에서 필요한 정보만 빠르게 찾는 높은 IOPS와 벡터 검색
- 초거대 병렬 I/O 및 희소 접근 성능
HBM: 연산 가속기로의 진화
고주파 모듈에서 매 토큰마다 발생하는 작업은 단순히 정보를 읽는 것을 넘어, 가중치를 읽고(Read), 수정하고(Modify), 다시 쓰는(Write) 복합 연산을 포함합니다. 이 '읽기-수정-쓰기(Read-Modify-Write)' 연산 폭증을 감당하려면 HBM4부터 베이스 다이에 TSMC N5 같은 첨단 로직 공정 도입이 필수적입니다.
이는 HBM이 수동적인 '데이터 탱크'를 넘어, 일부 연산을 직접 처리하는 PIM(Process-In-Memory)이자 가속기(Accelerator)의 일부로 격상됨을 의미합니다. 구글과 같은 빅테크가 JEDEC 표준을 넘어 자신들의 알고리즘에 최적화된 맞춤형 HBM을 요구하는 이유가 바로 여기에 있습니다.
CXL/SOCAMM: 지능형 데이터 파이프라인
Nested Learning 알고리즘의 업데이트 시점은 어느 정도 예측 가능합니다. 이 예측 가능성을 활용한 '프리페칭(Prefetching)' 기술은 CXL DRAM의 물리적 지연 시간이라는 약점을 효과적으로 숨기는 '지연 시간 은닉(Latency Hiding)'을 가능하게 합니다. GPU가 현재 데이터를 처리하는 동안, 시스템은 유휴 CXL 대역폭으로 다음 연산에 필요한 데이터를 HBM으로 미리 가져다 놓습니다.
CXL은 단순 메모리 용량 확장을 넘어 알고리즘의 리듬에 맞춰 데이터를 공급하는 '스마트 파이프라인'으로 진화합니다. 가장 적합한 폼팩터는 차세대 메모리 모듈 SOCAMM(LPCAMM2)입니다. LPDDR 기반 SOCAMM은 기존 DDR5 대비 절반 수준의 전력으로 2배 빠른 속도를 제공하며, 저전력·고속 특성으로 대규모 데이터 이동을 효율적으로 지원합니다.
SSD: L4 캐시로의 격상
페타바이트급 데이터를 저장하는 저주파 모듈의 핵심은 데이터 전체를 순차적으로 읽는 것이 아니라, 모델이 필요한 특정 파라미터 블록만 정확히 찾아내는 '희소 접근(Sparse Access)' 능력입니다. 이는 순차 읽기보다 높은 IOPS(초당 입출력 횟수)를 요구하는 랜덤 읽기 성능이 훨씬 중요해짐을 의미합니다.
SSD는 단순 저장소를 넘어, 컨트롤러 단에서 벡터 검색 같은 데이터 전처리를 수행하는 'Computational Storage'로 진화합니다. GPUDirect Storage 기술과 연계하여 GPU가 CPU를 거치지 않고 SSD에 직접 접근하고, SSD는 필요한 데이터만 필터링하여 전달함으로써 GPU 연산을 보조하는 가장 느리지만 가장 거대한 L4 캐시로 입지가 격상됩니다.
TPU 생태계 확장과 AI 반도체 경쟁 구도 변화
구글의 AI 전략은 모델 개발을 넘어 칩(TPU), 클라우드, 플랫폼을 아우르는 강력한 수직 계열화로 완성되고 있습니다. Gemini 3.0의 학습과 추론이 대부분 자체 TPU로 수행되었다는 점은 구글이 엔비디아 의존성에서 벗어나 독자적 AI 생태계를 구축했음을 의미하며, 엔비디아 독주 체제에 구조적 변화를 가져오는 중요한 변수입니다.
TPU vs GPU: 효율성 경쟁의 새로운 국면
구글 TPU
- 딥러닝 행렬 연산에 특화된 주문형 반도체(ASIC)
- 특정 작업에서 GPU 대비 월등히 높은 전력 효율
- 구글 클라우드 환경에 종속되어 범용성은 제한적
엔비디아 GPU
- 범용 병렬 컴퓨팅으로 확장
- 강력한 CUDA 소프트웨어 생태계
- 압도적인 시장 점유율과 폭넓은 적용 범위
구글은 TPU 6세대(Trillium), 7세대(Ironwood)로 이어지는 로드맵과 수만 개의 TPU를 하나의 슈퍼컴퓨터처럼 운용하는 'AI Hypercomputer' 아키텍처로 압도적인 비용 우위와 규모의 경제를 달성하고 있습니다. 엔비디아 GPU 구매와 외부 클라우드 임대에 의존하여 비용이 중첩되는 오픈AI나 앤트로픽의 '마진 스태킹 구조'와 극명한 대조를 이룹니다.
TPU 외부 공급의 전략적 의미
최근 구글이 앤트로픽, 메타 등 외부 기업에 TPU 판매를 확대하는 것은 시장에 중요한 시사점을 던집니다. 이는 단순히 '엔비디아 vs 구글'의 대결이 아니라, AI 가속기 시장의 경쟁 기준을 칩 가격 자체에서 전력 효율과 총소유비용(TCO)으로 전환시키고 있습니다.
당장 엔비디아의 독점적 지위에 대한 실존적 위협이라기보다는, AI 가속기 시장의 경쟁을 촉진하고 엔비디아의 높은 이익률에 압박을 가함으로써 전체 AI 인프라 비용을 제어하려는 다각적 포석으로 분석됩니다. 결과적으로 TPU든 GPU든 HBM 같은 핵심 부품을 필수적으로 소모하기에, 이러한 경쟁 심화는 오히려 삼성전자와 SK하이닉스 같은 핵심 부품 공급망의 중요성을 더욱 부각시킵니다.
TPU의 부상은 GPU를 완전히 대체하는 것이 아니라, 전체 AI 가속기 시장의 파이를 키우고 고객사들에게 공급망 다각화라는 새로운 선택지를 제공하는 동력으로 작용할 것입니다.
종합 전망 및 결론: 질적 슈퍼사이클의 도래

AI 경쟁 패러다임의 전환
AI 산업의 경쟁 패러다임은 '단일 모델의 성능'을 넘어 '엔드투엔드 운영체제의 완결성 및 경제성'으로 전환되고 있습니다. 소프트웨어 알고리즘, 하드웨어 인프라, 최종 서비스 생태계가 얼마나 유기적으로 결합되어 시너지를 내는지가 장기적 승패를 가릅니다.
단기적으로는 구글(통합 생태계), 오픈AI(선점 사용자), 앤트로픽(B2B 신뢰)이 각자의 강점을 기반으로 시장을 분할 점유하는 구도가 이어질 것입니다. 하지만 장기적으로는 진정한 개인화된 AI 에이전트를 구현하는 기업이 시장을 주도할 것입니다. 이를 위해서는 사용자와의 상호작용을 통해 실시간으로 배우고 성장하는 '지속적 학습' 기술이 필수적이며, 현재로서는 구글의 'Nested Learning' 아키텍처가 이 장기 비전에 가장 근접한 기술적 시도로 평가됩니다.
메모리 반도체 질적 슈퍼사이클의 도래
과거 컴퓨터 공학을 지배해 온 "소프트웨어는 하드웨어의 물리적 특성을 몰라도 된다"는 추상화의 원칙이 구글의 Nested Learning 아키텍처로 인해 붕괴되고 있습니다. 알고리즘이 생성하는 '업데이트 주파수'라는 메타 정보가 물리적 메모리 계층을 직접 제어하지 않으면 최적의 성능을 낼 수 없는 시대가 도래한 것입니다.
이는 "알고리즘을 모르면 메모리를 만들 수 없고, 하드웨어를 모르면 모델을 최적화할 수 없다"는 새로운 명제를 탄생시켰습니다. 이 필연적 결합은 메모리 반도체 기업의 가치 사슬 내 역할을 근본적으로 재정의합니다.
메모리 기업은 더 이상 표준 규격품을 대량 공급하는 데 그쳐서는 안 됩니다. 구글과 같은 빅테크의 알고리즘에 최적화된 로직과 기능을 통합한 솔루션을 제공하는 '시스템 솔루션 파트너'이자 AI 시스템의 공동 설계자로 변모해야 합니다.
구글의 새로운 AI 아키텍처는 소프트웨어 변화를 넘어, 하드웨어, 특히 메모리 반도체 산업에 거대한 파급효과를 가져올 전망입니다. '중첩 학습'의 다중 주파수 개념은 하드웨어의 '계층형 메모리' 구조와 직접 연결되며, 메모리 반도체에 대한 요구사항을 근본적으로 바꿉니다.
- 고주파 모듈: HBM 베이스 다이에 연산 기능이 내장된 맞춤형 HBM4 수요 견인
- 중주파 모듈: CXL DRAM과 SOCAMM을 알고리즘과 동기화된 '스마트 파이프라인'으로 격상
- 저주파 모듈: SSD를 단순 저장소에서 추론 과정의 능동적 참여자이자 지능형 연산 장치로 진화
이는 메모리 반도체가 단순 부품에서 지능형 연산 장치로 격상되는 '질적 슈퍼사이클'의 도래를 예고합니다.
최종 결론
구글은 기초 연구(아키텍처 혁신)와 수직 통합(인프라)이라는 양 날개로 장기적이고 구조적인 경쟁 우위를 확보하려는 전략을 구사하고 있습니다. 반면 오픈AI는 압도적인 시장 선점 효과를, 앤트로픽은 특정 B2B 시장에서의 깊이를 무기로 이에 맞서고 있습니다.
AI 산업은 이제 소프트웨어와 하드웨어의 경계가 허물어지는 새로운 국면에 진입했습니다. 소프트웨어의 청사진이 하드웨어의 미래 구조를 재정의하고, 알고리즘이 실리콘에 직접적인 물리적 요구사항을 부과하는 패러다임 전환이 일어나고 있습니다.
현재 목도하고 있는 메모리 슈퍼사이클은 과거의 단순한 수급 불균형에 따른 가격 반등이 아닙니다. 메모리 반도체가 단순 부품에서 벗어나 AI 연산의 일부를 담당하는 지능형 장치로 격상되면서 그 기술적 가치가 근본적으로 재평가되는 '질적(Qualitative) 전환'입니다.
이 필연적인 결합을 가장 성공적으로 구현하는 기업이 미래 AI 경쟁의 최종 승자가 될 것이며, 소프트웨어와 하드웨어의 공생이 만들어내는 이 거대한 구조적 변화의 중심에서 메모리 산업은 전례 없는 가치 상승의 기회를 맞이하고 있습니다.
Copyright 2025. 코드폴릭스 All rights reserved.

'주식 > 폴릭스 리포트' 카테고리의 다른 글
| SK하이닉스, 미국 ADR 상장 정말 할까? (1) | 2026.01.04 |
|---|---|
| AI 혁명의 제2막: 추론의 시대, 전력과 반도체가 이끄는 2026-2030 성장 로드맵 (1) | 2026.01.01 |
| 조선 및 방위 산업 성장주 기반 투자 포트폴리오 제안서 (1) | 2025.12.18 |
| 브로드컴(AVGO) 심층 분석: 역대급 실적과 주가 급락의 역설, AI 시대의 진정한 승자는 누구인가? (0) | 2025.12.15 |
| 미래를 만드는 로봇 군단: 대한민국 4대 그룹의 로봇 대전 완전 정복 (0) | 2025.12.12 |